Deep Learning 공부를 시작하면서 반복적으로 만나는 용어들이 있어 인터넷 검색을 통해 간단히 정리합니다. 이런 용어들을 접할때마다 계속해서 나를 괴롭힙니다만, 사실 이해하고 나면 그리 어렵지 않은 것들입니다.
인공지능, 머신러닝, 딥러닝
모두가 알듯이 인공지능은 최근에 새롭게 생겨난 것이 아니라 그 역사가 제법 길고 인공지능 연구는 이전 두번의 좌절이 있었고, 세번째 기회가 찾아 온것인데 이번에는 제대로 붐이 일고 있는 듯합니다.
인공지능(人工知能, artificial intelligence, AI)이란 수학적으로 표현할 수 없었던 복잡한 인간의 두뇌를 데이터를 기반으로 흉내를 내는 것으로 설명될 수 있습니다.
머신러닝(Machine Learning)은 “사람이 제공해준 데이터 항목을 가지고 컴퓨터가 학습한 다음 데이터의 규칙성을 찾아서 향후 주어지는 과제에 대해 판단을 하거나 예측을 하는 시스템”을 의미합니다.
예를 들어 신인 프로농구 선수의 선수 수명을 예측한다고 가정했을 때 기존 은퇴한 농구 선수들의 데이터(신체 조건, 각종 기록 등)를 학습시키고 그를 통해 은퇴 시기의 규칙성을 찾게 됩니다.
딥러닝은 “인공신경망을 활용하여 사람의 뇌와 비슷한 구조로 이해하여, 컴퓨터가 스스로 학습해 향후 주어지는 과제에 대한 판단 및 예측을 하는 시스템”으로 설명됩니다.
예를 들어 고양이인지 강아지인지 인식하는데 각종 데이터를 학습시키는 것이 아니라 많은 수의 고양이 사진과 강아지 사진을 입력하여 고양이와 강아지를 분류해주면 딥러닝은 사람의 뇌가 인식하는 방식으로 학습을 합니다. 이 과정을 통해 딥러닝 네트워크는 적절한 분류체계를 찾아내어 이후 입력되는 사진이 강아지인지 고양이인지 분류합니다.
머신 러닝의 종류
머신 러닝에는 지도학습, 비지도학습, 강화학습 세가지 종류가 있습니다.
지도학습(Supervised Learning)
- 입력과 결과값(label) 이용한 학습
- 분류(classfication), 회귀(regression)
- (학습모델) SVM, Decision Tree, kNN, 선형/로지스틱 회귀
비지도학습(Unsupervised Learning)
- 입력만을 이용한 학습
- 군집화(clustering), 압축(compression)
- (학습모델) K-means 클러스터링
강화학습(Reinforcement Learning)
- 결과값 대신 리워드(reward) 주어짐
- Action Selection, Policy Learning
- (학습모델) MDP(Markov Decision Process)
지도학습은 입력값과 결과값을 제공하여 학습을 시키는 방법입니다. 비지도학습은 결과값 없이 입력값만을 이용하여 학습을 시키는 방법이고, 강화학습은 결과값 대신 어떤 일을 잘했을 때 보상을 주는 방법으로 학습을 시켜서 보상을 최대화하는 방향으로 학습이 진행됩니다.
손실 함수(Loss Function)
손실 함수는 신경망(Neural network)을 학습할 때 학습 상태에 대한 측정 지표로 자주 사용되는 것으로 신경망의 가중치 매개 변수들이 스스로 특징을 찾아 가기에 이 가중치 값이 최적이 되도록 해야 하는데, 잘 찾아가고 있는지를 판단할 때 사용됩니다.
-
평균제곱오차 (Mean Squared Error)
예측하는 값이랑 실제 값의 차이를 제곱하여 평균을 낸 값으로 통계에서 자주 사용되는 표현입니다. 예측 값과 실제 값의 차이가 클수록 평균제곱오차의 값도 커진다는 것은 이 값이 작을수록 예측력이 좋다는 의미입니다.

-
교차 엔트로피 오차 (Cross Entropy Error)
로그의 밑이 e인 자연로그를 예측값에 씌워서 실제 값과 곱한 후 전체 값을 합한 후 음수로 변환한 값을 의미합니다.

일반화와 최적화
일반화(Generalization)
학습 데이터와 Input data가 달라져도 출력에 대한 성능 차이가 나지 않게 하는 것을 일반화라고 합니다.
즉, 모델은 Training data를 가지고 모델링을 하는데 모델링 하는 목적은 Training data가 아니라 다른 외부의 data를 모델에 집어 넣어도 Training data로 모델을 학습시켜 얻은 Accuracy와 비슷한 값을 가지게 하는 것이 목적입니다. 이 말은 거의 비슷한 출력을 얻어 모델을 이용하는 것과 같습니다. 그래서, 일반화는 다른 외부의 data를 넣어도 Training data로 모델을 학습한 것과 거의 비슷한 결과를 얻는 것을 말합니다. Training data로 모델을 학습 시킬 때 가능한 정확하게 일반화를 해야 좋은 모델을 얻고, 적용을 할 수 있게 됩니다.
최적화(Optimization)
최적화는 신경망 분야에서 손실함수의 값을 최소화하는 하이퍼 파라미터(Hyper Parameter)의 값을 찾는 것을 말합니다. 여기서 하이퍼 파라미터(Hyper Parameter)는 사용자가 직접 정의할 수 있는 Parameter를 말하는데, 쉽게 말해서, 사람이 파라미터 값을 조절할 수 있는 것들을 말합니다. 예를 들어서, batch-size라던지 아니면 Learning-rate 라던지 등 모델에 관한 사용자가 조절할 수 있는 파라미터를 말합니다. 이와 관련하여, 최적화와 하이퍼 파라미터를 조절하는 최적화 방법은 대표적으로 확률적 경사하강법(Stochastic Gradient Descent, SGD)가 있습니다. SGD는 경사하강법에 관하여 이해를 하면 됩니다. 2차 함수가 있을 때, Learning-rate(lr)에 따라서 하강을 합니다. lr이 작으면 하강하는 속도가 느려져 학습을 시키는데 시간을 많이 걸리고, lr이 너무 크면 하강하는 폭이 커져서 결국엔 학습이 발산적으로 이루어집니다. 그래서, 적절한 lr을 줘야 합니다. 여기서, lr은 위에서 설명했던 하이퍼 파라미터입니다.
Perceptron
인공 신경망 모형의 하나인 퍼셉트론은 1957년에 처음 고안된 알고리즘으로 동물의 신경계를 본따 만들었기 때문에 개념적으로나 형태로나 비슷한 부분이 많습니다.
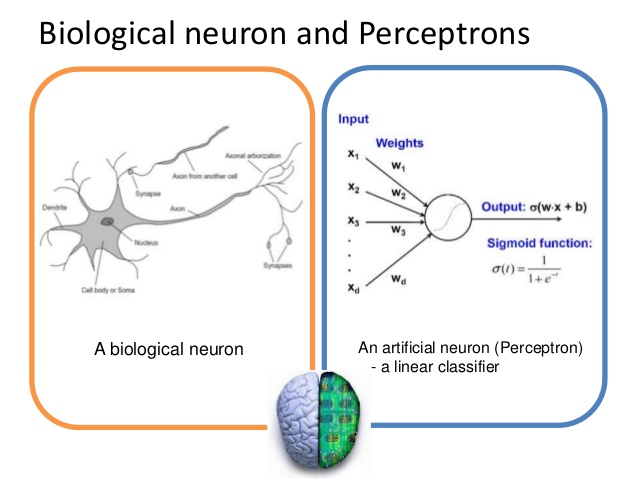
퍼셉트론은 다수의 신호를 입력받아서 하나의 신호를 출력한다. 이것은 뉴런이 전기신호를 내보내 정보를 전달하는 것과 비슷해 보이고, 뉴런의 수사돌기나 축색돌기처럼 신호를 전달하는 역할을 퍼센트론에서는 가중치(weight)가 수행한다고 볼 수 있습니다. 가중치는 입력신에 의해 계산되고 신호의 총합이 정해진 임계값을 넘었을 때 1을 출력하고 넘지 못하면 0 또는 -1을 출력합니다. 각 입력신호는 고유한 가중치가 부여되고 가중치가 클수록 해당 신호가 중요하다고 판단됩니다. 기계학습은 가중치의 값을 정하는 작업이라고 할 수 있습니다.
경사하강법
최적화란, 여러가지 허용되는 값들 중에서 주어진 기준을 가장 잘 만족하는 것을 선택하는 것을 의미하며, 최적화 종류로는 대표적으로 유전 알고리즘인 조합 최적화, 경사 하강법인 함수 최적화 방법이 있습니다.
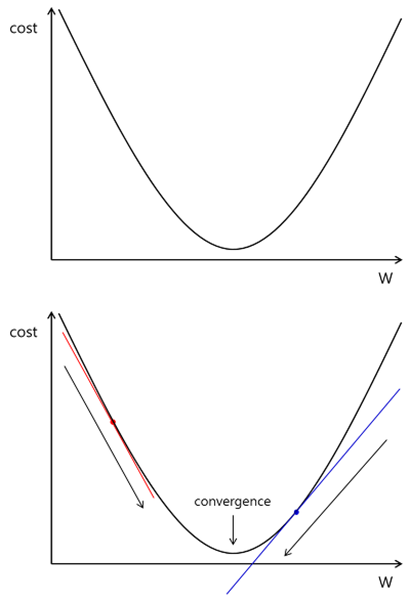
경사하강법은 해당 함수의 최소값 위치를 찾기 위해 비용 함수(cost function)의 그레디언트 반대 방향으로 정의한 step size를 조금씩 이동하면서 최적의 파라미터를 찾는 방법입니다. 여기서 그레디언트는 파라미터에 대해 편미분한 벡터를 의미하며 이 파라미터를 반복적으로 조금씩 이동하는 것이 관건입니다.
선형 회귀 모델에서의 비용함수를 아래와 같이 정의할 수 있습니다.
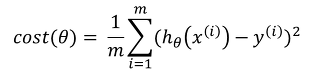
비용을 줄이기 위해 변경되는 W의 파라미터의 상관관계를 그래프로 나타낸다면 비용의 값이 최소가 되는 것은 W의 값이 가운데로 수렴하게 된다는 것을 의미합니다. 결국 그래프 위에 랜덤하게 파라미터가 정해지면 해당 파라미터의 위치로부터 최소값을 찾아 탐색하는 기준으로 경사도를 구하게 됩니다. 빨간점 위치에서 경사의 기울기는 음수이기 때문에 W의 값을 증가시키게 되고, 파란점 위치에서 경사의 기울기는 양수이기 때문에 W의 값을 감소시키게 됩니다.
오차역전파 (Error Backpropagation)
기계학습은 입력에서 출력으로 가중치를 업데이트하면서 활성화 함수를 통해서 결과값을 가져오는 과정을 거치게 됩니다. 이렇게 입력값을 전파하는 것을 순전파(Foward Propagation)라고 합니다. 한번 순전파 했지만 출력값이 정확하지는 않을 수 있습니다. 임의로 설정한 가중치가 입력에 의해서 한번 업데이트 되긴 했지만 많은 문제를 가지고 있을 수 있습니다.
역전파 방법은 결과 값을 통해서 다시 역으로 입력 방향으로 오차를 다시 보내며 가중치를 재업데이트하는 것을 의미합니다. 물론 결과에 영향을 많이 미친 노드는 더 많은 오차를 돌려줄 것입니다.
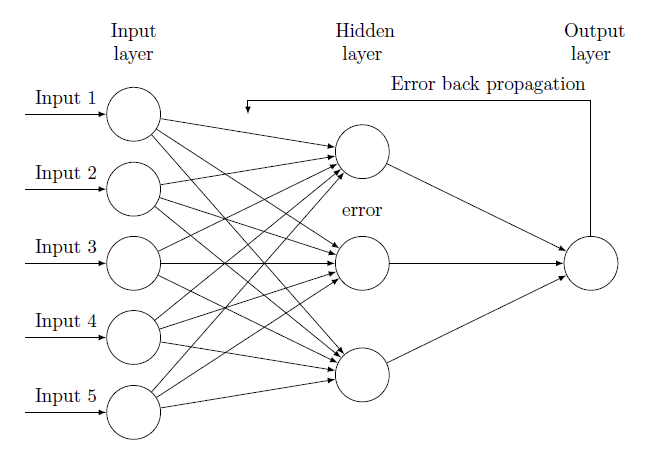
입력이 들어오는 순전파 반향으로 output layer에서 결과 값이 나옵니다. 결과값은 오차를 가지고 되는데 역전파는 이 오차를 다시 역방향으로 hidden layer와 input layer로 오차를 다시 보내면서 가중치를 계산하면서 output에서 발생했던 오차를 적용시키는 것입니다.
활성화 함수(Activation Function)
딥러닝 네트워크에서는 노트에 들어오는 값들에 대해 곧바로 다음 레이어로 전달하지 않고 주로 비선형 함수를 통과시킨 후 전달합니다. 이 때 사용하는 함수를 활성화 함수(Activation Function)라고 말합니다. 여기서 주로 비선형 함수를 사용하는 이유는 선형함수를 사용할 시 층을 깊게 하는 의미가 줄어들기 때문입니다.
활성화 함수는 sigmoid, ReLU 등 여러 종류가 있으나 가장 대표적으로 사용되는 것은 ReLU입니다. sigmoid는 초기에는 자주 사용되었지만 많은 단점들 때문에 현재는 잘 사용되지 않습니다만 활성화 함수의 개념을 이해하기 위해서 함께 설명합니다.
Sigmoid 함수
Sigmoid 함수는 Logistic 함수라고도 불리며, 선형인 Multi-perceptron에서 비선형 값을 얻기 위해 사용하기 시작했습니다.
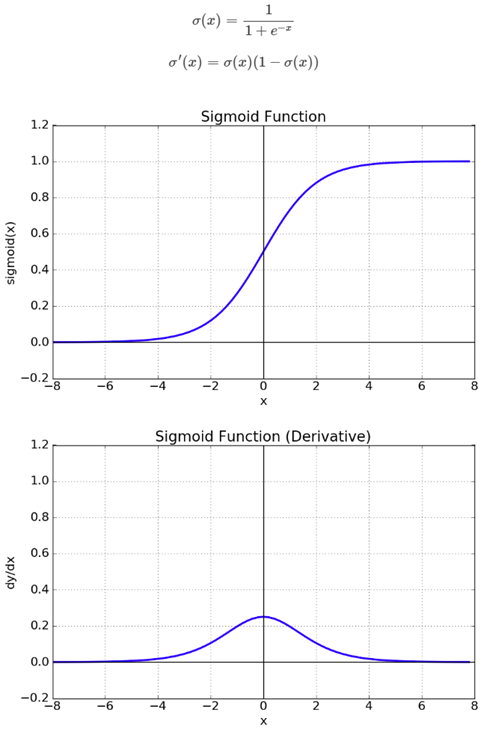
Sigmoid 함수의 특징은 다음과 같습니다.
- 우선 함수값이 (0, 1)로 제한된다.
- 중간 값은 1/2이다.
- 매우 큰 값을 가지면 함수값은 거의 1이며, 매우 작은 값을 가지면 거의 0이다.
Sigmoid 함수의 단점은 다음과 같습니다.
-
Gradient Vanishing 현상이 발생합니다. 미분함수에 대해 x = 0에서 최대값 1/4을 가지고, input 값이 일정이상 올라가면 미분값이 거의 0에 수렴하게 됩니다. 이는 x 값이 커질수록 Gradient backpropagation 시 미분값이 소실될 가능성이 크게 됩니다. - 함수값 중심이 0이 아니다. 함수값 중심이 0이 아니기 때문에 같은 방향으로 update를 하는데에도 zigzag로 계산되기 때문에 학습이 느리게 됩니다. 이러한 단점들 때문에 최근에는 잘 사용되지 않는다.
ReLu 함수(Rectified Linear Unit)
ReLU는 최근(2018년 기준) 많이 사용되는 활성화 함수입니다.
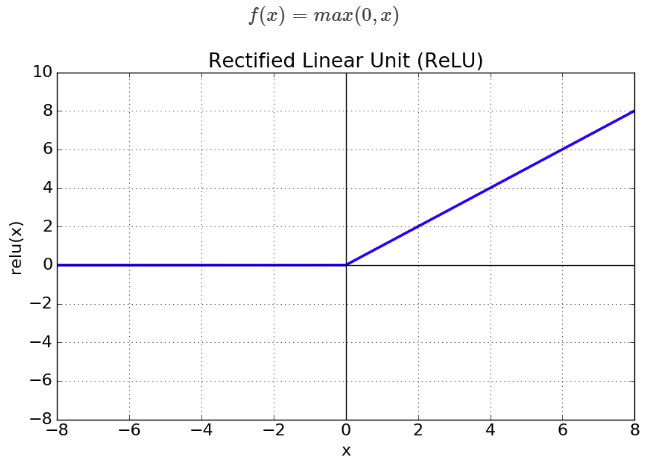
ReLU 함수의 특징은 다음과 같습니다.
- x > 0 이면 기울기가 1인 직선이고, x < 0 이면 함수값이 0이 된다.
- sigmoid, tanh 함수보다 학습이 훨씬 빠르다.
- 연산 비용이 크지않고 구현이 매우 간단하다.
- x < 0 인 값들에 대해서는 기울기가 0이기 때문에 뉴런이 죽을 수 있다.
Epoch, Step, Batch
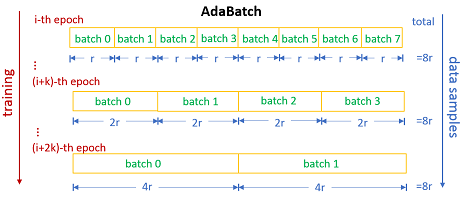
-
Epoch
전체 샘플 데이터를 이용하여 한 바퀴를 돌며 학습하는 것을 의미합니다. 따라서 2 epochs는 전체 샘플 데이터를 이용하여 2번 돌며 학습한 것입니다. -
Step
Weight와 Bias를 1회 업데이트 하는 것을 1 Setp이라고 부릅니다. -
Batch Size
1회 Step에서 사용한 데이터의 수를 의미합니다. 따라서 Batch size가 20이고 Step이 5이면 약 100개의 데이터를 이용한 것이 됩니다.
s = (n * e) / b
n = num of sample e = epochs b = batch size s = step
가중치 초기화
네트워크를 학습할 때 가중치(weight)의 초기화가 매우 중요합니다. Forward와 backward 계산을 반복해서 진행하면, 최초 전달된 값과 예측된 값의 차이가 최소가 되는 가중치를 발견하게 되고, 네트워크의 전체 layer에서 사용하는 가중치를 초기화하는 pre-training 과정을 수행하게 됩니다. 초기화가 잘된 상태로 학습을 시작하면 학습 시간이 짧아지기 때문에 이 과정을 학습(learning)이라고 부르지 않고 fine tuning이라고 부릅니다.
대표적인 가중치의 초기화 방법중에는 2010년에 발표된 xavier 초기화와 2015년에 xavier 초기화를 응용한 He 초기화가 있습니다. 이들 방법은 매우 간단하며 결과가 훌륭합니다.

- Xavier - 입력값(fan-in)과 출력값(fan-out) 사이의 난수를 선택해서 입력값의 제곱근으로 나눈 값을 사용
- He - 입력값(fan-in)을 반으로 나눈 제곱근을 사용하며, 분모가 작아지기 때문에 xavier보다 넓은 범위의 난수를 생성